
By 2025, data-sphere experts forecast that worldwide data will exceed 175 zettabytes—and this trend is growing so fast that our global storage capacity cannot physically keep up with the payload.
This raises important questions: how much of this information should we store and save as “data”? But most importantly, how do enterprises “know” what data has value?
Jun 14, 2023 by Craig Woolard

In today’s digital age, unstructured data has become the lifeblood of modern business. Access to quality data is driving innovation, improving insights, and enhancing decision-making within the most agile organizations. But with the rise of unstructured data, modern organizations are faced with a new challenge: how to make sense of this massive data deluge.
This blog will answer the question, “What is unstructured data?” Then, we will examine the global challenges that modern enterprises are facing as they navigate the rapid growth of unstructured data and its unique opportunities.
Finally, we will discuss how data-driven enterprises can use next-gen AI-driven intelligent document processing (IDP) to “unlock” the business intelligence stuck in unstructured documents.
Keep in touch
What is unstructured data?
Gartner defines the data in unstructured documents as machine-printed or handwritten content lacking predefined “rules” or guidelines. Traditionally, computers have had to be programmed to follow rules in order to locate information of interest in structured databases and related formats.
However, unstructured data that lacks predefined rules is much more common in the real world. Unstructured data could be free-form text, such as the body of an email, or non-textual, such as a photo containing handwriting.
Unstructured data is also challenging to capture. Traditional “rules-based” approaches, such as the ones used in standalone Optical Character Recognition (OCR) and Robotic Process Automation (RPA), are limited when it comes to extracting data that lacks structure
For example, RPA “robots” are limited in their ability to learn from experience; the bots can only do what they are programmed to do and do not improve or adapt over time without human intervention.
Consequently, since legacy technologies like RPA can only handle rules-based, repetitive tasks, they struggle to extract information from unstructured documents, which leads to critical information being missing.
The global challenges of unstructured data
The IDC Global DataSphere analyzes global data trends and reports on the quantity of data created worldwide. It also looks at how much data is stored across various storage media. In 2020, IDC researchers determined that the world produced more than 64 zettabytes of data.
Since then, this global uptick in growth has skyrocketed so quickly that the amount of data we produce over the next five years is projected to outpace our global capacity to store it, meaning we save less of the data we create each year.
In 2020, IDC researchers determined that the world produced more than 64 zettabytes of data.
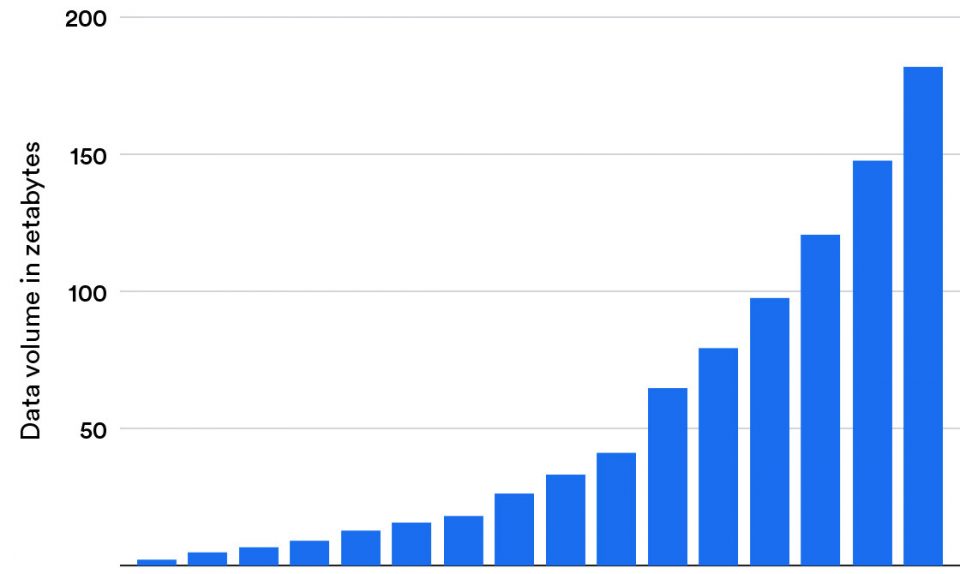
By 2025, data-sphere experts have forecast that worldwide data will exceed 175 zettabytes. This trend is growing so fast that our global storage capacity, physically, cannot keep up with the payload. In this current reality, it raises an important question: how much of this information should we store and save as “data”?
…this global uptick in growth has skyrocketed so quickly that the amount of data we produce over the next five years is projected to outpace our global capacity to store it, meaning we save less of the data we create each year.
Since the cloud increasingly determines how we store, consume, and engage with information, the rate at which enterprises produce data is double that of consumers. While not all data created is mission-critical or needs to be saved, how can enterprises determine what data has value?
Understanding the growth of unstructured data within organizations
Big data experts estimate that unstructured data accounts for 90% of all new enterprise data. This trend reveals that unstructured data is growing 55-65% every year—a rate three times faster than the growth of structured data. Yet only 18% of organizations are taking advantage of unstructured information.
The reality is that the bulk of an organization’s data today is “unstructured.” That’s because modern customer information comes in many forms:
- emails
- text messages
- social media posts
- PDFs
- handwritten scanned documents, and more.
Without a method to mine valuable data from these documents, an organization is simply unable to adapt to changing conditions. So what about the other 82%? These organizations lack the technology to “unlock” business intelligence stuck in their most valuable resource: unstructured documents.
If you can’t unlock the business intelligence trapped in legacy document processes, then the value within remains unobtainable.
The capability to unlock valuable intelligence is severely blocked within organizations with highly regulated document-centric processes, such as banking institutions. Older heritage document processes are a real barrier to digital transformation. If you can’t unlock the business intelligence trapped in legacy document processes, then the value within remains unobtainable.
So what can be done about it?
How IDP overcomes the challenges of unstructured data
Intelligent document processing (IDP) is a type of business workflow automation that uses next-gen artificial intelligence (AI), machine learning (ML), and natural language processing (NLP) to read documents like humans.
IDP brings modern AI/cognitive capabilities to workflow automation software, enabling organizations to reduce errors and improve the accuracy of their data. Many tasks, including data entry, automated document classification, and data extraction, can be successfully automated with IDP.
The main goal of IDP is to transform your organization’s semi-structured and unstructured documents into useful, structured data.
IDP can also integrate data with existing SAPs, ERPs, accounting software, databases, and legacy RPA tools—creating the most advanced solution for the global challenges of rapidly growing unstructured data.
The main goal of IDP is to transform your organization’s semi-structured and unstructured documents into useful, structured data. No matter what documents your organization handles, IDP scans content and interprets context—along with the author’s intent—to streamline the entire document workflow with above-human accuracy.
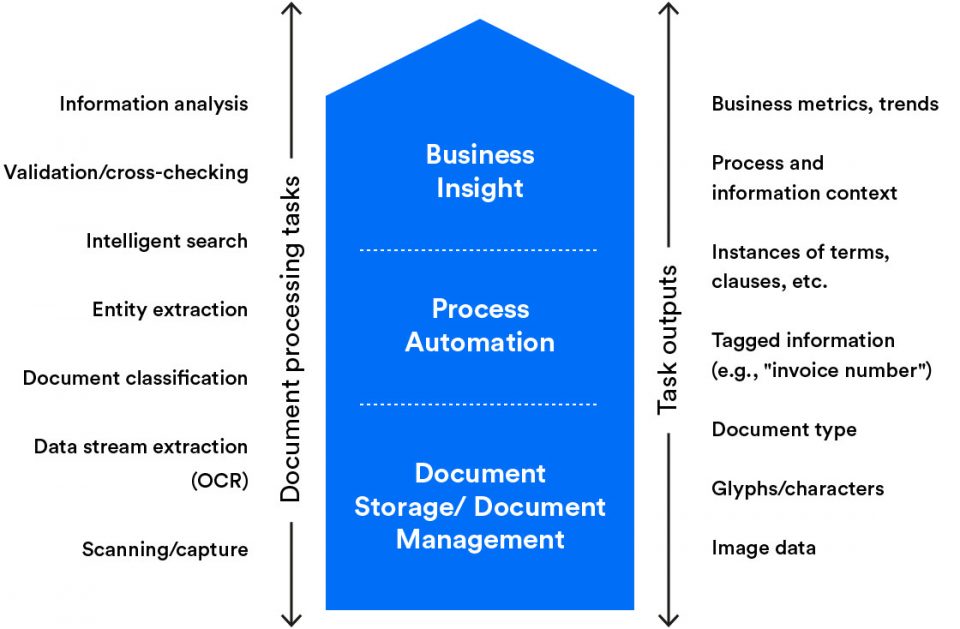
Since IDP aims to convert unstructured and semi-structured documents into structured data, intelligent document processing offers organizations the modern AI-driven automation technology they need to unlock the intelligence stuck inside any document. This leads to a wide range of business use cases, including invoice processing, contract automation, and automated email classification and processing systems.
Organizations that leverage next-gen IDP technology to transform unstructured data into accessible data that is easy to use will come with many competitive advantages—but the immediate benefits are:
- faster processing speeds
- more efficient business processes
- streamlined document management workflows
- improved data quality,
- enhanced decision-making
For a complete understanding of intelligent document processing and the use cases that can help your organization, check out our Guide to Intelligent Document Processing for more.
Conclusion
Unstructured data presents both a challenge and an opportunity. Unlocking its potential provides the business intelligence that will give agile enterprises a real competitive advantage. But how can enterprises know whether or not data has potential value if there’s too much “friction” to unlock it? The answer is Intelligent Document Processing (IDP).
Transform unstructured data into business value with our AI-driven automation platform today
Learn how we helped Markerstudy reduce its claims processing time by 40%. Additionally, learn how we reduced total claim processing time by 80% for another multinational insurance partner — cutting down manual tasks from 10 minutes to just two minutes per claim.
- Speak with an expert — tell us about your specific use case.
- Get a personalized demo — schedule a demo, and our Heroes will get in touch!